
Abstract
Real-world objects frequently undergo state transformations. From an apple being cut into pieces to a butterfly emerging from its cocoon, tracking through these changes is important for understanding real-world objects and dynamics. However, existing methods often lose track of the target object after transformation, due to significant changes in object appearance. To address this limitation, we introduce the task of Track Any State: tracking objects through transformations while detecting and describing state changes, accompanied by a new benchmark dataset, VOST-TAS.
To tackle this problem, we present TubeletGraph, a zero-shot system that recovers missing objects after transformation and maps out how object states are evolving over time. TubeletGraph first identifies potentially overlooked tracks, and determines whether they should be integrated based on semantic and proximity priors. Then, it reasons about the added tracks and generates a state graph describing each observed transformation. TubeletGraph achieves state-of-the-art tracking performance under transformations, while demonstrating deeper understanding of object transformations and promising capabilities in temporal grounding and semantic reasoning for complex object transformations.
Motivation
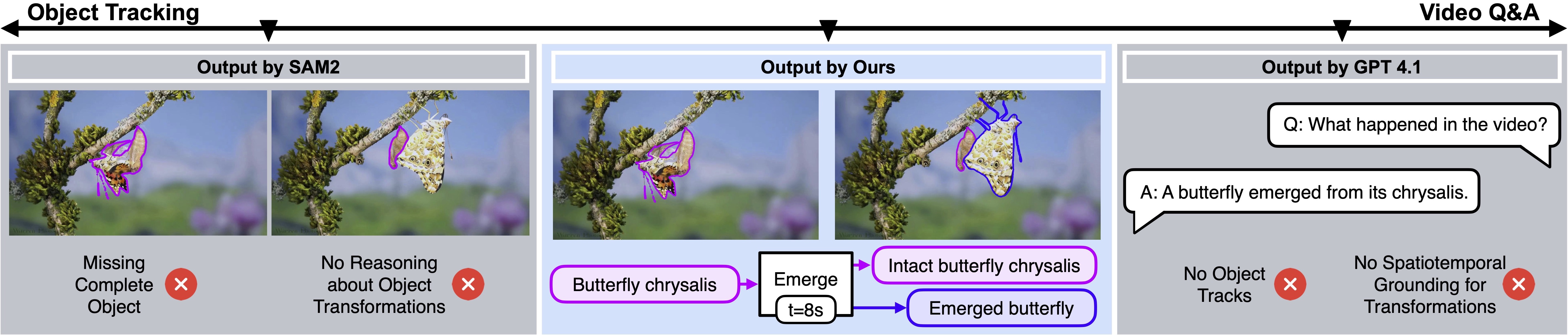
Problem:
Existing object trackers often fail to keep track of the complete object when transformations occur (left).
On the other hand, current VLM systems can provide descriptions of state changes, but they can't ground them spatiotemporally to the target objects in the video (right).
Solution: We propose TubeletGraph, a zero-shot system that can map out how the object evolves over time, detect the underlying state changes, and track the resulting objects of these changes.
Methodology
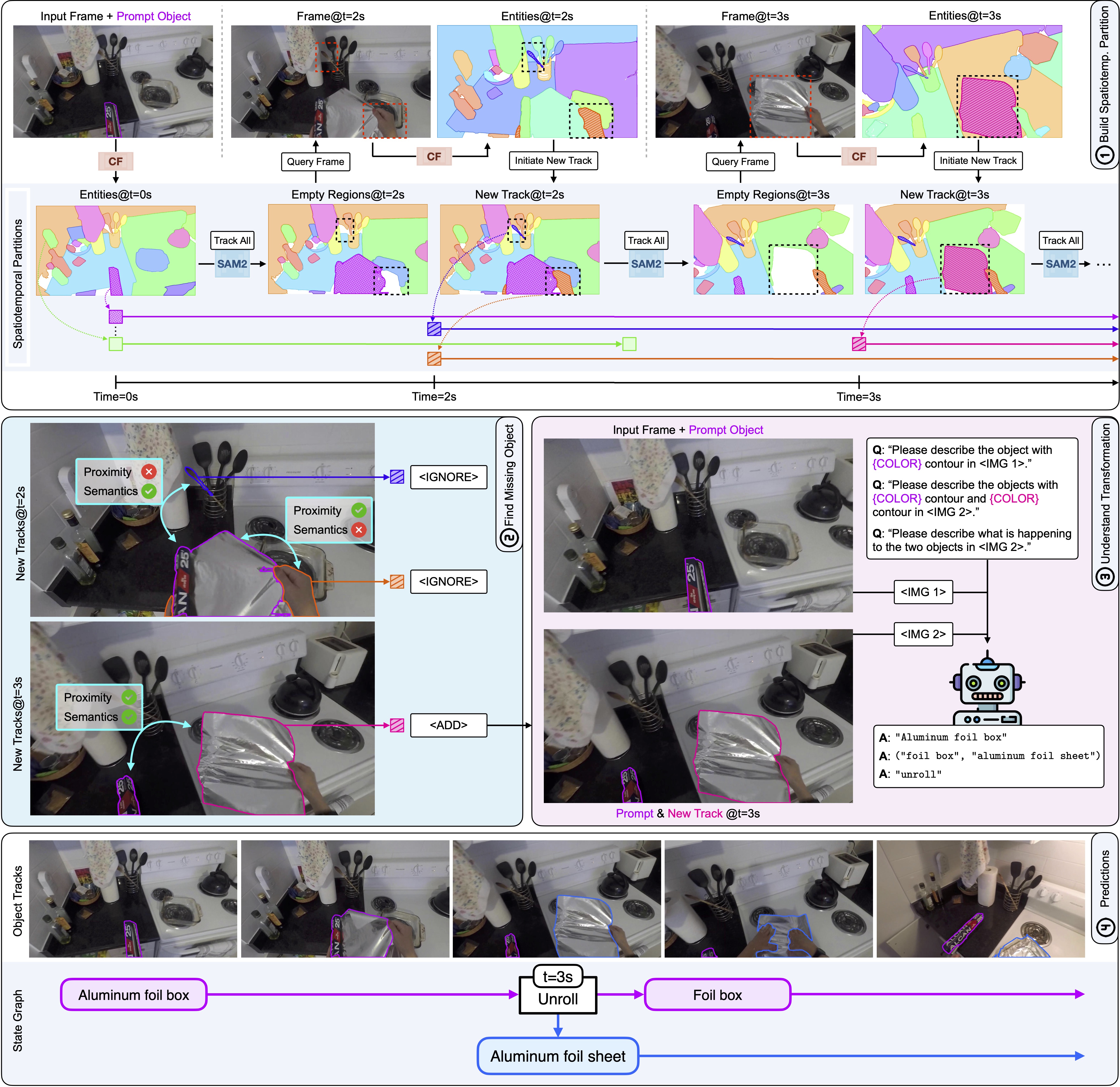
Overview of TubeletGraph:
(1) We first partition the input video into a set of “tubelets” by tracking all regions from the start and initiating new tracks when untracked pixels emerge;
(2) We then use semantic and spatial proximity priors to filter which candidates to include in the final prediction;
(3) Finally, for each added object, we query a vision-language model to build a state graph for each detected transformation and its resulting effect.
VOST-TAS

Overview of VOST-TAS:
We introduce VOST-TAS (TrackAnyState), an extended version of the VOST validation set with explicit transformation annotations for tracking and understanding object state changes in videos.
Specifically, the dataset contains 57 video instances, 108 transformations, and 293 annotated resulting objects.
Qualitative examples are provided above and the full dataset is available HERE.
Qualitative Results
We first showcase TubeletGraph's predictions on M\(^3\)-VOS and VOST.
For each instance, we show the input video with initial object prompt in cyan (top-left), the predicted object tracks (top-right), and the predicted state graph (bottom).
M\(^3\)-VOS
Video ID: 0334_cut_fruit_1

Video ID: 0315_paint_cream_4

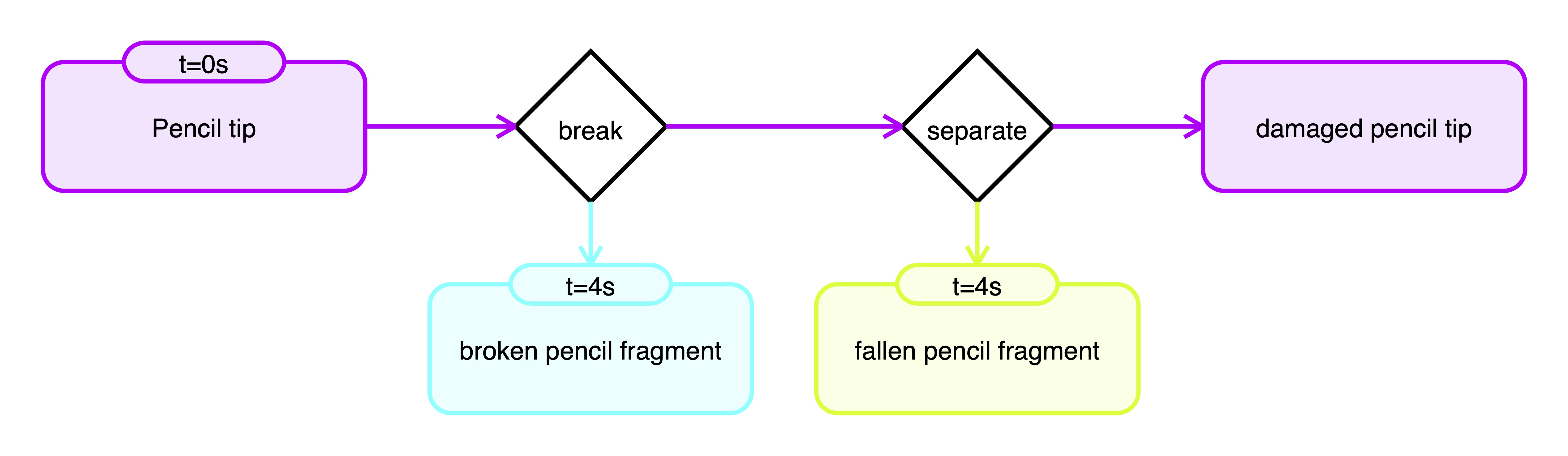
Video ID: 0269_press_pencil_1
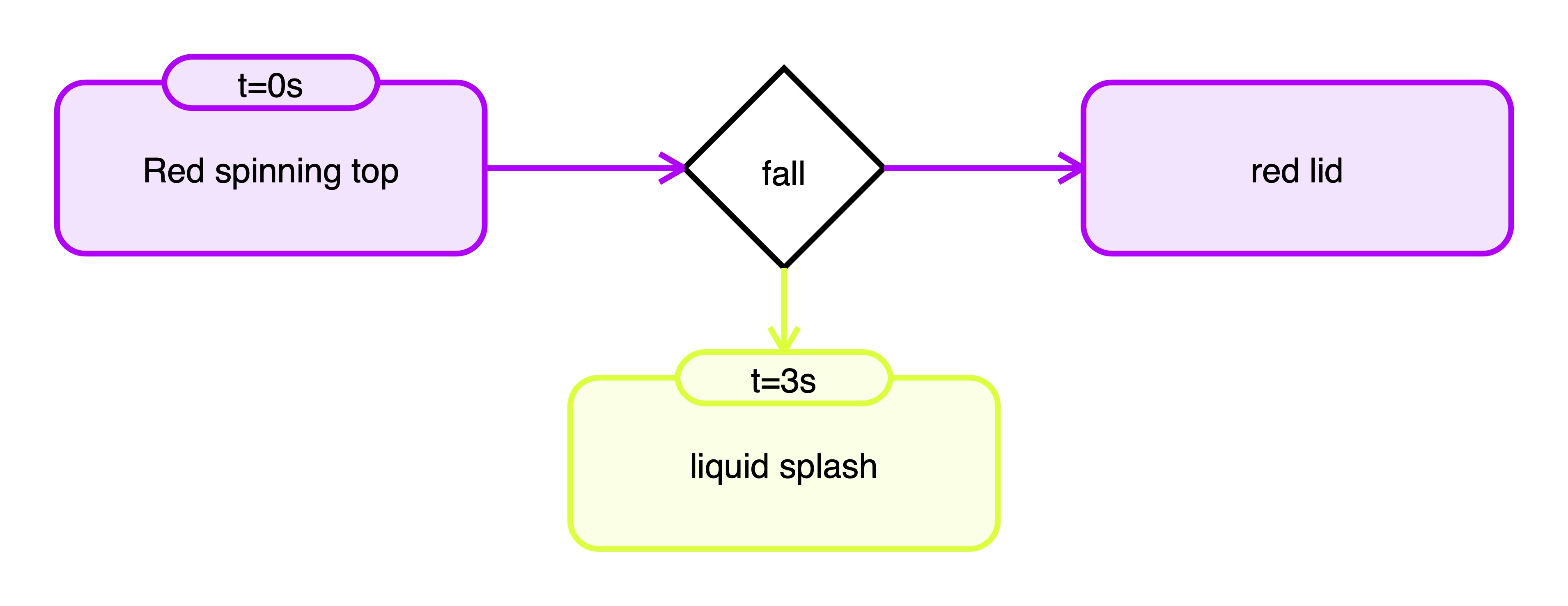
Video ID: 0250_splash_liquid_2
Video ID: 0369_cut_cheese_3

Video ID: 0292_peel_fruit_3

VOST
Video ID: 555_tear_aluminium_foil
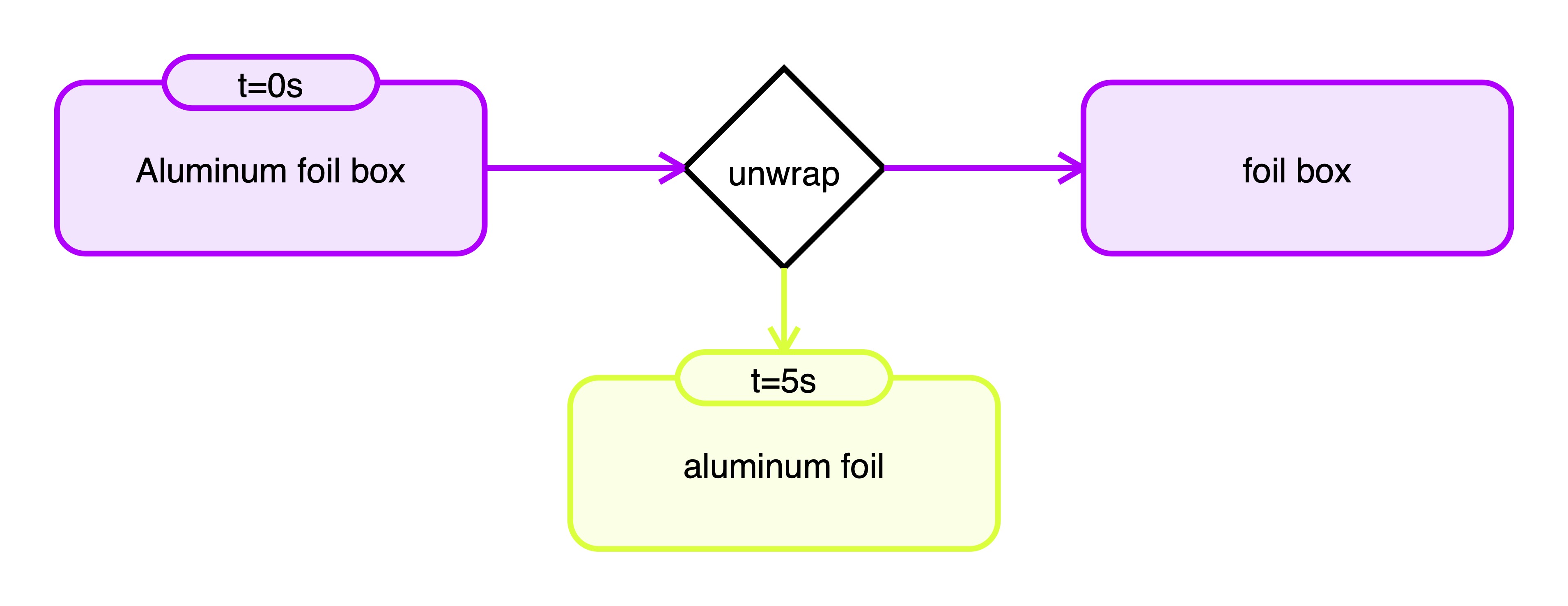
Video ID: 4021_cut_broccoli

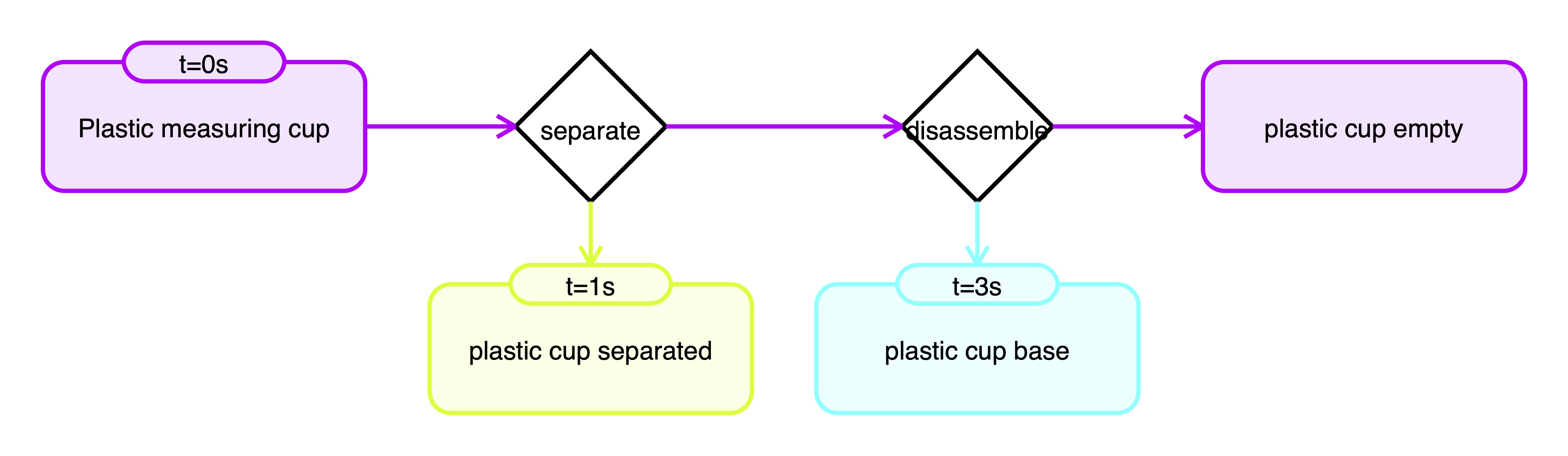
Video ID: 9671_split_cups
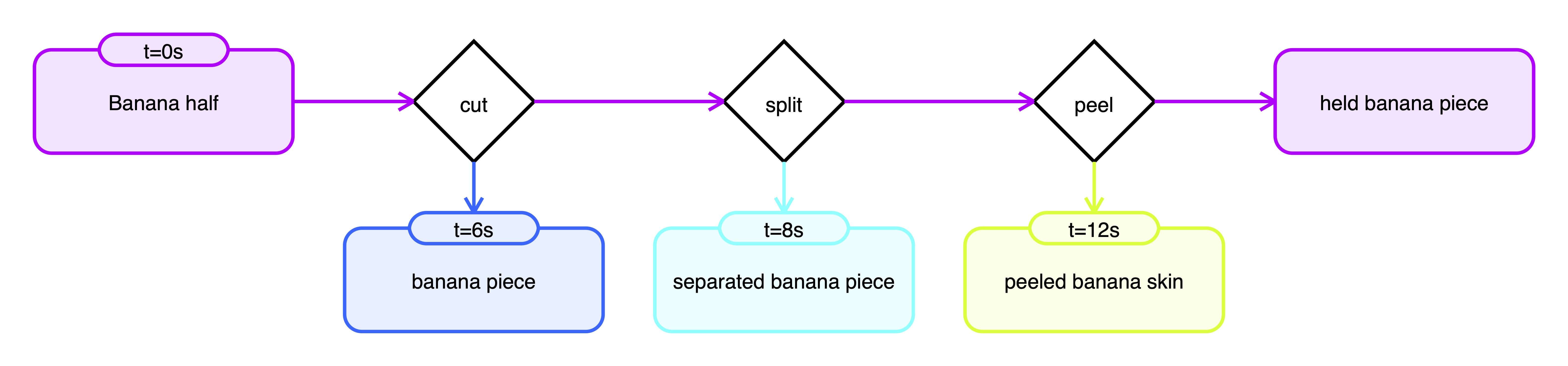
Video ID: 3161_peel_banana
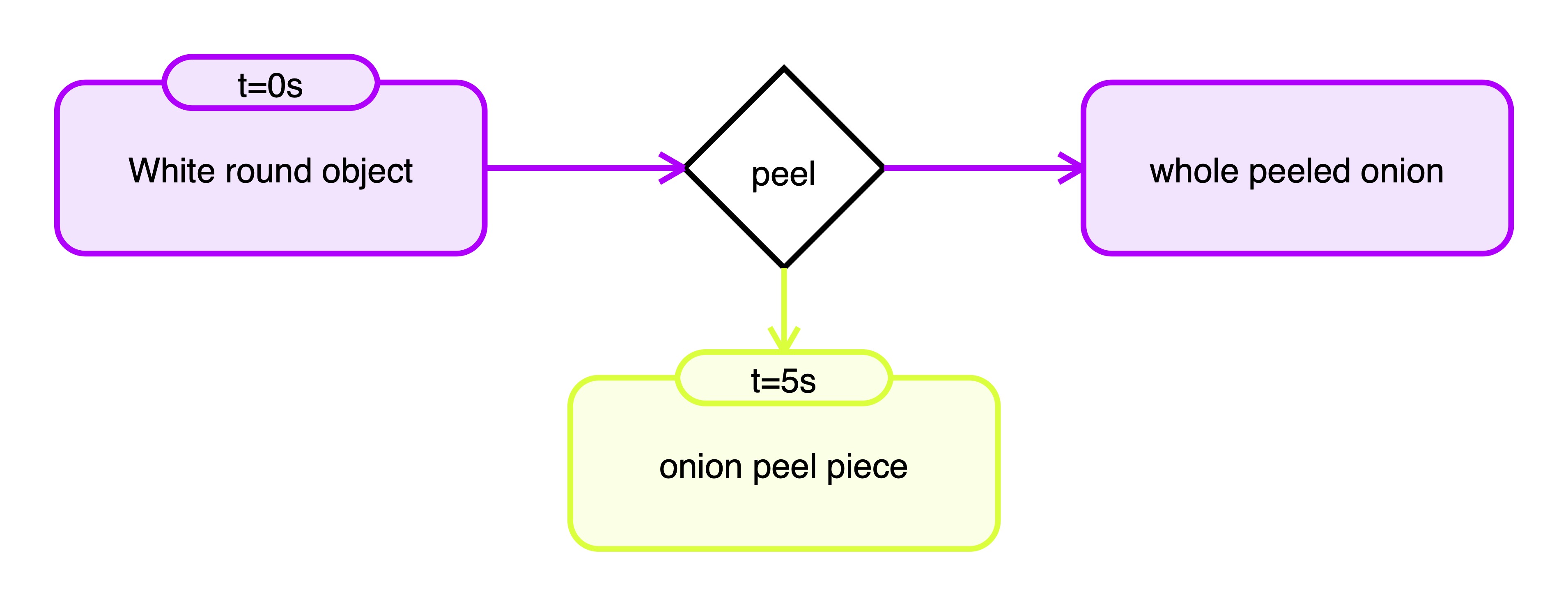
Video ID: 3316_peel_onion
Video ID: 556_cut_tomato
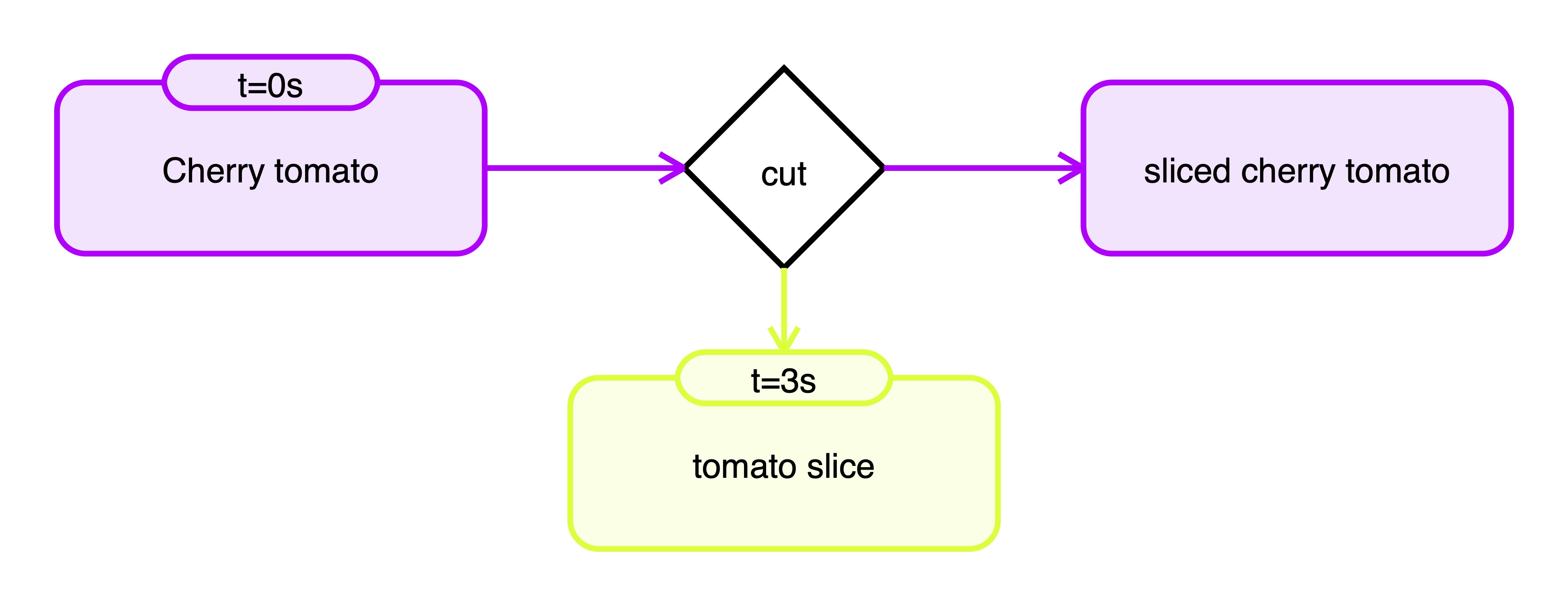
Object Tracking Comparisons
We now compare TubeletGraph against prior works on M\(^3\)-VOS and VOST.
For each input video, we show the predictions of SAM2.1 (finetuned on VOST train set), SAM2.1 (off-the-shelf), SAMURAI, TubeletGraph (with all resulting objects merged), and the ground truth annotations.
M\(^3\)-VOS
VOST
Failure Cases
In both cases below, the tracking errors made by the base tracker (SAM2.1) are propagated to the final prediction.
Additionally shown in Row 2, the existing vision-language model fails to recognize the object (measuring tap) from singular frames only with substantial occlusion.
Video ID: 0340_fry_omelet_1

Video ID: 7359_fold_tape_measure
BibTeX
@article{sun2025tracking,
title={Tracking and Understanding Object Transformations},
author={Sun, Yihong and Yang, Xinyu and Sun, Jennifer J and Hariharan, Bharath},
journal={Advances in Neural Information Processing Systems},
year={2025}
}